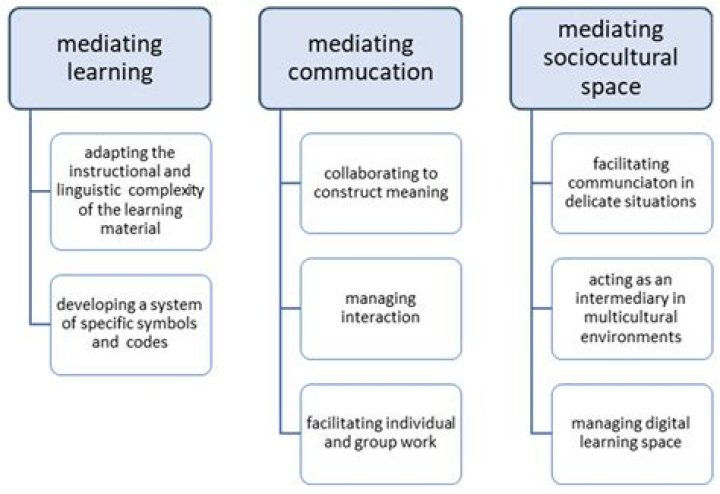
Create Documents by adding Fields;Create an IndexWriter and add documents to it with addDocument();Call QueryParser. parse() to build a query from a string; and.Create an IndexSearcher and pass the query to its search() method.
What is Lucene query Parser?
Although Lucene provides the ability to create your own queries through its API, it also provides a rich query language through the Query Parser, a lexer which interprets a string into a Lucene Query using JavaCC. … In other words, the query parser is designed for human-entered text, not for program-generated text.
Does Kibana use Lucene?
Lucene query syntax is available to Kibana users who opt out of the Kibana Query Language. Full documentation for this syntax is available as part of Elasticsearch query string syntax. … To search for a range of values, use the bracketed range syntax, [START_VALUE TO END_VALUE] .
What is Lucene filter?
lucene-filter transforms a lucene query into a function which returns whether an object matches the query, using the ‘boost’ set by the query. Returning the data when matching is also possible using .What type of database is Lucene?
Developer(s)Apache Software FoundationOperating systemCross-platformTypeSearch and indexLicenseApache License 2.0Websitelucene.apache.org
What is a Lucene index?
In a nutshell, when lucene indexes a document it breaks it down into a number of terms. It then stores the terms in an index file where each term is associated with the documents that contain it. You could think of it as a bit like a hashtable.
How do you write Lucene query?
- Field The ID or name of a specific container of information in a database. …
- Terms Items you would like to search for in a database. …
- Operators/Modifiers A symbol or keyword used to denote a logical operation.
How do you find special characters in Lucene?
Lucene supports single and multiple character wildcard searches. To perform a single character wildcard search use the “?” symbol. To perform a multiple character wildcard search use the “*” symbol. You can also use the wildcard searches in the middle of a term.Is Lucene case sensitive?
Lucene search is case-sensitive, but all input is usually lowercased when passing through QueryParser, so it feels like it is case insensitive (This is the case of the findBySimpleQuery() method. In other words, don’t lowercase your input before indexing, and don’t lowercase your queries.
What is the difference between Solr and Lucene?SOLR is a wrapper over Lucene index. It is simple to understand: SOLR is car and Lucene is its engine. Apache Lucene is the vanilla version for the search engine while Apache Solr is inheriting Lucene with new inbuilt features which Apache Lucene don’t provide out of the box.
Article first time published onIs not Lucene query?
Lucene does not allow NOT queries as a single term for the same reason it does not allow prefix queries – to perform either, the engine would have to look through each document to ascertain whether the document is/is not a hit. … not in the result set) documents in the index, but without a key to look them up by.
Is Lucene an Elasticsearch?
Lucene or Apache Lucene is an open-source Java library used as a search engine. Elasticsearch is built on top of Lucene. Elasticsearch converts Lucene into a distributed system/search engine for scaling horizontally.
How do I write Elasticsearch query in Grafana?
First, you need to go to Data Sources in Grafana, and choose Elasticsearch. You put your index name here. (Look at the date field.) And in the query, you will see that Date Histogram will be automatically set to date.
How do I use Lucene query in Kibana?
- To perform a free text search, simply enter a text string. …
- To search for a value in a specific field, prefix the value with the name of the field. …
- To search for a range of values, you can use the bracketed range syntax, [START_VALUE TO END_VALUE] .
Is Lucene a NoSQL database?
Apache Solr is both a search engine and a distributed document database with SQL support. Here’s how to get started. Apache Solr is a subproject of Apache Lucene, which is the indexing technology behind most recently created search and index technology. … It is a NoSQL database with transactional support.
What language is Lucene written in?
Apache Lucene™ is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
What is Lucene in Hadoop?
The Apache Lucene™ project develops open-source search software. … Lucene Core is a Java library providing powerful indexing and search features, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities.
What is a phrase query?
A Query that matches documents containing a particular sequence of terms. A PhraseQuery is built by QueryParser for input like “new york” . This query may be combined with other terms or queries with a BooleanQuery . NOTE: All terms in the phrase must match, even those at the same position.
What is Kibana query language?
The Kibana Query Language (KQL) is a simple syntax for filtering Elasticsearch data using free text search or field-based search. KQL is only used for filtering data, and has no role in sorting or aggregating the data. KQL is able to suggest field names, values, and operators as you type.
What is query DSL?
Querydsl is an extensive Java framework, which allows for the generation of type-safe queries in a syntax similar to SQL. It currently has a wide range of support for various backends through the use of separate modules including JPA, JDO, SQL, Java collections, RDF, Lucene, Hibernate Search, and MongoDB.
How do you pronounce Apache SOLR?
Solr (pronounced “solar”) is an open-source enterprise-search platform, written in Java.
What is Lucene document?
In Lucene, a Document is the unit of search and index. An index consists of one or more Documents. Indexing involves adding Documents to an IndexWriter, and searching involves retrieving Documents from an index via an IndexSearcher.
Why is Lucene used?
Lucene offers powerful features like scalable and high-performance indexing of the documents and search capability through a simple API. It utilizes powerful, accurate and efficient search algorithms written in Java. … Lucene provides search over documents; where a document is essentially a collection of fields.
What is Lucene based search?
Essentially Apache Lucene is a full-text search engine software library that provides a Java-based search and indexing platform. Using Java it lets you add search capabilities to websites or applications. It takes content and adds it to a full-text index which can then be used to perform queries.
How do you escape Lucene query?
Lucene supports escaping special characters that are part of the query syntax. To escape a special character, precede the character with a backslash ( \ ).
Does Azure search use Lucene?
2 Answers. According to this Microsoft page the full text search is built on Lucene. “The full text search engine in Azure Search is built on Apache Lucene, an industry standard in information retrieval.”
Which of the following search operators in Azure search needs to be escaped when passing them through the rest API?
- The NOT operator – only needs to be escaped if it’s the first character after a whitespace. …
- The suffix operator * only needs to be escaped if it’s the last character before a whitespace.
Does Google use Lucene?
Despite these open-source bona fides, it’s still surprising to see someone at Google adopting Solr, an open-source search server based on Apache Lucene, for its All for Good site. Google is the world’s search market leader by a very long stretch. … Why use Solr?
Why is Solr used?
Solr is a popular search platform for Web sites because it can index and search multiple sites and return recommendations for related content based on the search query’s taxonomy. Solr is also a popular search platform for enterprise search because it can be used to index and search documents and email attachments.
What is Solr and Elasticsearch?
The main difference between Solr and Elasticsearch is that Solr is a completely open-source search engine. Whereas Elasticsearch though open source is still managed by Elastic’s employees. Solr supports text search while Elasticsearch is mainly used for analytical querying, filtering, and grouping.
How do you write KQL?
To specify a phrase in a KQL query, you must use double quotation marks. KQL queries don’t support suffix matching, so you can’t use the wildcard operator before a phrase in free-text queries. However, you can use the wildcard operator after a phrase.